
老规矩,先上项目地址:https://github.com/index-tts/index-tts
Tips:文末看官方演示视频!👇
大家好,这里是红鱼AI。今天要给大家安利一个真正能让你"开口跪"的开源项目——IndexTTS。
说实话,作为一个混迹AI圈子的人,我见过太多语音合成工具了。有些是商业软件,收费不说,效果还一言难尽;有些是开源项目,但上手难度堪比登天。直到我遇到了IndexTTS,这个项目直接刷新了我对TTS(文本转语音)的认知。

为什么说它是"黑科技"?
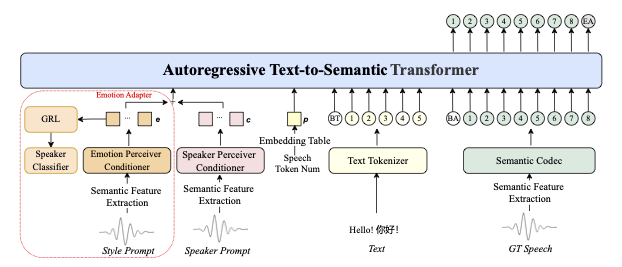
首先,它不是那种只会读稿子的机器人声音,而是能生成带有情感、有温度的语音。你想要悲伤的、开心的、愤怒的语气,它都能给你整出来。更绝的是,它还支持多语言,不管是中文、英文还是其他语言,都能hold住。
最让我惊喜的是它的音质,用了BigVGAN声码器,生成的音频清晰度简直惊人。而且它基于GPT架构进行语音生成,这就意味着它有很强的理解能力,知道在什么时候该用什么语调。
开始你的AI声音之旅
好了,废话不多说,直接上干货。接下来我就手把手教大家怎么用这个项目。
第一步:环境准备
在开始之前,你需要确保你的电脑上有Python环境。建议使用Python 3.8或更高版本。如果你还没装Python,先去官网下载一个。
关于硬件配置,这个项目对GPU有一定要求。如果你想体验流畅的生成效果,最好有一块NVIDIA显卡。当然,CPU也能跑,但速度嘛,就像骑着共享单车追高铁——能追上,但你得有耐心。
第二步:克隆项目
打开终端(或者命令行),输入以下命令把项目克隆到本地:
git clone https://github.com/index-tts/index-tts.git
然后进入项目目录:
cd index-tts
第三步:安装依赖
这个项目用了很多第三方库,安装之前建议你创建一个虚拟环境。用conda的可以这样做:
conda create -n indextts python=3.10
conda activate indextts
或者用venv:
python -m venv venv
source venv/bin/activate # Linux/Mac
venv\Scripts\activate # Windows
激活虚拟环境后,安装依赖:
pip install -e .
这里有个小细节,如果你在安装过程中遇到某些包下载速度太慢,可以试试换国内的镜像源。不过这是Python开发的基础操作了,我就不展开说了。
第四步:下载模型文件
这个项目的核心是那些预训练模型。你需要把它们下载下来。模型的配置文件在 checkpoints/config.yaml 里面。
根据项目文档,模型文件可以通过官方提供的链接下载。下载后记得把它们放到正确的目录下,不然程序找不到模型会报错。
第五步:快速体验
安装完成后,你可以先跑个简单的例子看看效果。项目提供了Python API,用起来非常简单。
最基础的使用方式是这样的:
from indextts import IndexTTS
初始化模型
tts = IndexTTS()
生成语音
audio = tts.tts("你好,我是IndexTTS,很高兴认识你。")
保存音频
import soundfile as sf
sf.write("output.wav", audio, 22050)
就这么简单,几行代码就能生成语音。运行这段代码后,你会在当前目录下得到一个output.wav文件,用播放器打开听听看。
第六步:玩转情感控制
IndexTTS最厉害的功能之一就是情感控制。你可以让同一个文本用不同的情感读出来。
比如,你想让文字读得更悲伤一点:
audio = tts.tts("今天天气真好", emotion="sad")
或者更开心一点:
audio = tts.tts("今天天气真好", emotion="happy")
项目里还提供了一些示例音频文件,在examples目录下,包括voice_01.wav到voice_12.wav,这些是不同情感的参考音频。你可以参考这些音频的效果来调整自己的生成参数。
第七步:使用Web界面
如果你不喜欢写代码,或者想更直观地调整参数,项目还提供了Web界面。启动方式很简单:
python webui.py
然后在浏览器里打开 http://localhost:7860 (具体端口以启动信息为准),你就能看到一个友好的图形界面了。
在Web界面里,你可以:
输入要转换的文本
选择参考音频
调整各种参数,比如语速、音调、情感等
实时预览生成的音频
下载生成好的音频文件
这个界面设计得很人性化,就算不懂技术的人也能快速上手。
第八步:进阶玩法
当你熟悉了基本操作后,可以尝试一些进阶功能。
流式生成:如果你需要实时生成语音,比如语音助手那种场景,可以使用流式生成模式。这样可以一边生成一边播放,用户体验会好很多。
多语言支持:IndexTTS支持多种语言,你可以在配置文件中设置语言参数。需要注意的是,不同语言的效果可能会有差异,建议自己测试一下。
自定义音频风格:如果你有自己的音频样例,可以用它来定义语音的风格。这样生成出来的声音会更符合你的预期。
实际应用场景
说了这么多,这个东西到底能干嘛呢?我来举几个实际的应用场景。
场景一:短视频配音
现在做短视频的人越来越多,但很多人配音是个大问题。要么声音不好听,要么不会说标准的普通话。用IndexTTS,你可以生成各种风格的配音,轻松搞定视频旁白。而且你可以调整情感,让配音更符合视频的内容。
场景二:有声书制作
如果你是个主播,或者想自己做有声书,这个工具能帮大忙。你只需要准备好文本,然后用IndexTTS生成音频。当然,如果你想要更个性化的声音,可以用自己的声音样例来训练。不过这个功能可能需要一些技术背景。
场景三:游戏角色配音
独立游戏开发者经常面临一个问题:没钱请专业配音演员。IndexTTS可以作为替代方案,为游戏角色生成配音。特别是对于那些次要角色,或者对话量比较大的NPC,这个工具能省不少事。
场景四:教育内容制作
制作在线课程或者教育视频时,配音也是必不可少的。用IndexTTS可以快速生成讲解音频,而且风格统一,听起来很专业。
场景五:辅助工具
对于视力障碍的用户,TTS技术是必不可少的辅助工具。IndexTTS的高质量语音输出可以作为屏幕阅读器的后端,提供更好的用户体验。
一些小贴士
在使用过程中,有几个小经验分享给大家。
首先,文本预处理很重要。虽然IndexTTS能处理各种文本,但如果你提前处理好标点符号、数字、英文等内容,生成的效果会更好。比如,把"123"写成"一百二十三"或者"one two three",视具体需求而定。
其次,参数调整需要耐心。很多时候第一次生成的效果不是最理想的,需要不断调整各种参数才能达到最佳效果。建议先从默认参数开始,然后逐步调整。
再次,参考音频的选择很关键。好的参考音频能让生成的语音更接近你想要的效果。项目提供了一些示例音频,你可以多试试。
最后,记得定期更新项目。开源项目更新很快,新版本可能会修复一些bug,或者增加新功能。
演示视频
写在最后
IndexTTS是一个真正实用的开源项目,无论是对于开发者还是普通用户,都很有价值。它降低了语音合成的门槛,让更多人能够享受到高质量的TTS技术。
当然,它也有一些局限性。比如,生成的声音虽然已经很接近真人,但细听还是能分辨出来。而且,对于特别复杂的情感表达,可能还需要进一步优化。但考虑到它是开源免费的,这些小缺点完全可以接受。
如果你对语音合成感兴趣,或者在工作中需要用到TTS技术,不妨试试IndexTTS。相信我,你会爱上这个工具的。
好了,今天的分享就到这里。如果你觉得这篇文章对你有帮助,欢迎点赞、转发。我们下期再见!