
老规矩,先上项目链接:https://github.com/resemble-ai/chatterbox
最近AI界又卷起来了,这次是语音克隆赛道。Resemble AI开源了一个叫Chatterbox的项目,直接把语音克隆的门槛降到了地板上。三个模型,23种语言,零样本克隆,关键是——完全免费,还能本地跑。
咱今天就来扒一扒这个项目,看看它到底有多香。

先说结论:这东西能干嘛?
简单来说,Chatterbox就是一个文本转语音(TTS)和语音克隆工具包。你给它一段文字,它能生成语音;你给它一段参考音频,它能用任何人的声音念这段文字。而且不是那种机械的电子音,是那种听起来跟真人差不多的自然语音。
更绝的是,它还有语音转换功能。你录一段自己的声音,然后指定一个目标声音(比如某个明星),它就能把你的声音转换成那个明星的音色,但说的还是你原本的话。
三个模型怎么选?
项目里一共有三个模型版本,咱们逐个说。
Chatterbox-Turbo:速度王
350M参数的小钢炮,主打一个快。专门为低延迟语音助手设计的,延迟可以压到200ms以内。这个模型还支持副语言标签,什么意思呢?就是你在文本里加个 [laugh]、[chuckle]、[cough],生成的语音里真的会有笑声、轻笑、咳嗽的声音。这细节,绝了。
适合场景:实时语音助手、需要快速生成的应用、对延迟敏感的项目。
Chatterbox-Multilingual:语言通
500M参数的大哥,支持23种语言。中文、英语、法语、德语、日语、韩语……你想得到的它基本都有。而且它是零样本语音克隆,随便给个参考音频就能克隆那个人的声音。
适合场景:多语言应用、国际化项目、需要克隆多种语言声音的需求。
Chatterbox:创意大师
同样是500M参数,但这个版本支持更多高级参数调节。比如CFG(Classifier-Free Guidance)权重、夸张度调节这些。虽然功能多,但用起来稍微复杂点,适合想要精细控制生成效果的朋友。
适合场景:创意配音、有声书制作、需要精细调整语音风格的项目。
怎么安装?两步搞定
首先你得有个Python环境,Python 3.10以上就行。
第一种方法,直接用pip:
pip install chatterbox-tts
第二种方法,从源码安装:
git clone https://github.com/resemble-ai/chatterbox.git
cd chatterbox
pip install -e .
建议用第二种,虽然麻烦点,但你可以修改代码,而且所有依赖版本都锁定了,不容易出问题。
注意一下,项目在Debian 11、Python 3.11环境下测试的,用其他环境可能会有兼容性问题。
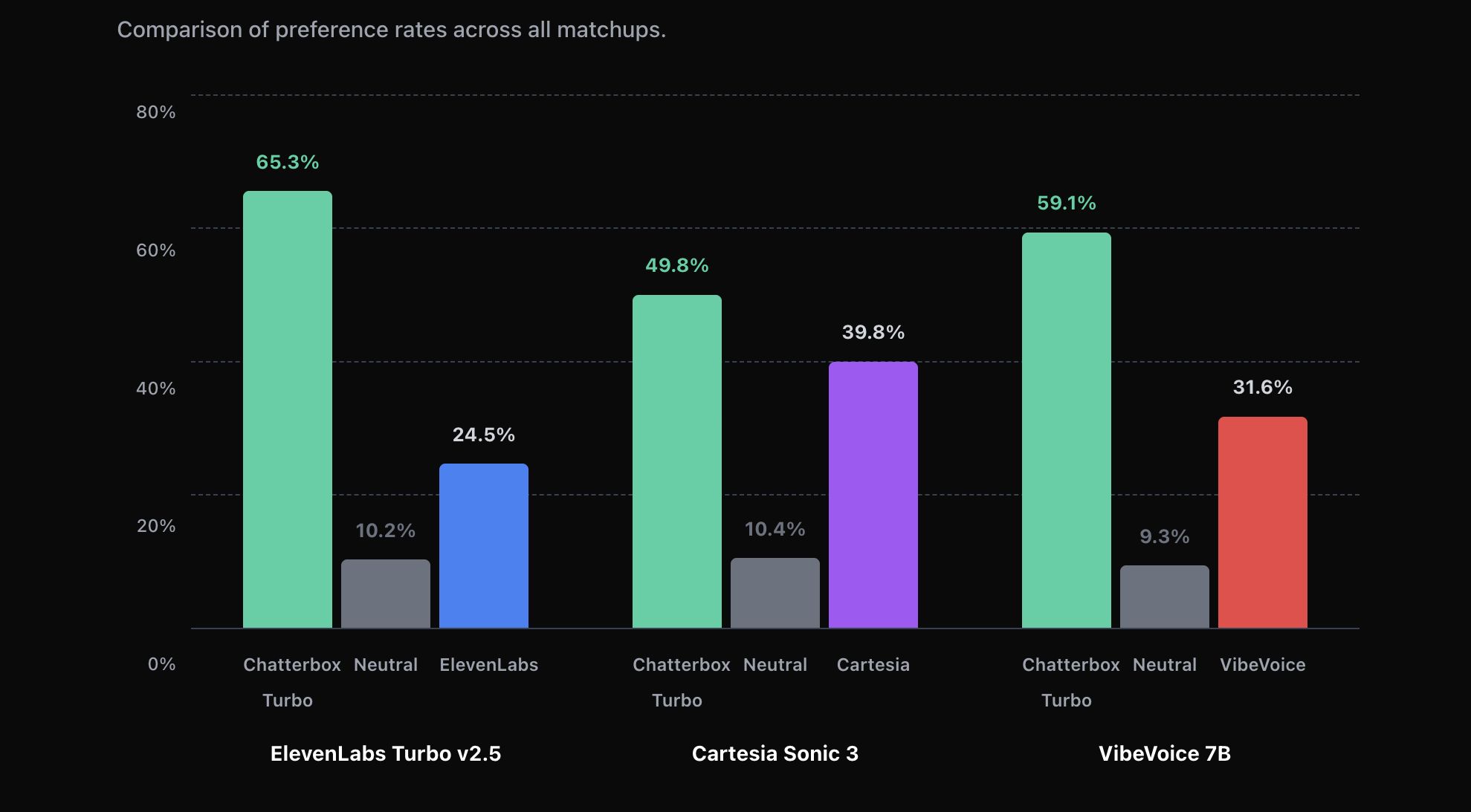
基础用法:从零到生成
咱们先看最基础的文本转语音。
英文TTS
import torchaudio as ta
from chatterbox.tts import ChatterboxTTS
model = ChatterboxTTS.from_pretrained(device="cuda")
text = "Ezreal and Jinx teamed up with Ahri, Yasuo, and Teemo to take down the enemy's Nexus in an epic late-game pentakill."
wav = model.generate(text)
ta.save("test-english.wav", wav, model.sr)
就这么简单,加载模型,生成,保存。注意device参数,有GPU就用cuda,Mac用mps,没有就用cpu。
多语言TTS
from chatterbox.mtl_tts import ChatterboxMultilingualTTS
multilingual_model = ChatterboxMultilingualTTS.from_pretrained(device="cuda")
法语:
french_text = "Bonjour, comment ça va? Ceci est le modèle de synthèse vocale multilingue Chatterbox."
wav_french = multilingual_model.generate(french_text, language_id="fr")
ta.save("test-french.wav", wav_french, multilingual_model.sr)
中文:
chinese_text = "你好,今天天气真不错,希望你有一个愉快的周末。"
wav_chinese = multilingual_model.generate(chinese_text, language_id="zh")
ta.save("test-chinese.wav", wav_chinese, multilingual_model.sr)
中文支持怎么样?这么说吧,能听懂,但还是有口音。毕竟是国外团队做的模型,中文训练数据可能没那么多。不过日常用用问题不大。
Turbo版本:加上副语言标签
from chatterbox.tts_turbo import ChatterboxTurboTTS
model = ChatterboxTurboTTS.from_pretrained(device="cuda")
text = "Oh, that's hilarious! [chuckle] Um anyway, we do have a new model in store. It's the SkyNet T-800 series and it's got basically everything."
wav = model.generate(text)
ta.save("test-turbo.wav", wav, model.sr)
试试把[laugh]、[cough]这些标签加到文本里,效果很有趣。
零样本语音克隆:这才是真·黑科技
这是最有趣的部分。你只需要给模型一个10秒左右的参考音频,它就能学习那个人的声音特征,然后用这个声音说任何你想说的话。
基础语音克隆
AUDIO_PROMPT_PATH = "your_10s_ref_clip.wav"
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH)
ta.save("test-clone.wav", wav, model.sr)
就这么简单。参考音频最好是清晰、干净、没有背景噪音的,时长5-15秒最合适。太短学不到特征,太长容易影响生成速度。
多语言语音克隆
注意一个小坑:参考音频的语言要和你要生成的语言一致。不然可能会有口音问题。比如你用中文参考音频去生成法语,那个法语可能会带中文口音。
怎么解决?把cfg_weight参数调为0:
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH, cfg_weight=0)
语音转换:变成别人的声音
除了TTS,Chatterbox还支持语音转换。就是你说话,但出来的声音是别人的。
from chatterbox.vc import ChatterboxVC
AUDIO_PATH = "your_recording.wav" # 你的录音
TARGET_VOICE_PATH = "target_voice.wav" # 目标声音
model = ChatterboxVC.from_pretrained(device)
wav = model.generate(
audio=AUDIO_PATH,
target_voice_path=TARGET_VOICE_PATH,
)
ta.save("testvc.wav", wav, model.sr)
这个功能有啥用?想象一下,你可以把任何人的声音转换成你喜欢的声音。比如把新闻主播的声音转换成某个动漫角色的声音,是不是很有趣?
高级参数:玩出花样
如果你想更精细地控制生成效果,有几个参数可以调。
Exaggeration:夸张度
默认是0.5,范围大概在0到2之间。
数值越大,语音越有表现力,语速也会加快。
夸张的演讲可以试试:
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH, exaggeration=1.5)
CFG Weight:分类器自由引导权重
默认0.5,范围0到1。
数值越小,生成的语音越贴近参考音频的声音风格;数值越大,生成的语音越接近模型本身的"平均"声音。
想保留更多参考音频的特征,就把cfg_weight调小点:
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH, cfg_weight=0.3)
组合使用
戏剧性的旁白:
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH, exaggeration=0.8, cfg_weight=0.3)
新闻主播风格:
wav = model.generate(text, audio_prompt_path=AUDIO_PROMPT_PATH, exaggeration=0.3, cfg_weight=0.7)
Web界面:不用写代码也能用
不想写代码?没问题,项目里还有Gradio界面。
gradio_tts_app.py:基础TTS界面
gradio_tts_turbo_app.py:Turbo版本界面
gradio_vc_app.py:语音转换界面
multilingual_app.py:多语言TTS界面
运行方式:
python gradio_tts_app.py
然后浏览器打开它给的地址(一般是 http://127.0.0.1:7860),就能用界面操作了。上传音频、输入文本、点生成,完事。
硬件需求:你跑得动吗?
这是个实际问题,咱们得说实话。
Chatterbox-Turbo(350M参数):至少需要6GB显存(GPU),CPU也行但会慢点。
Chatterbox和Chatterbox-Multilingual(500M参数):至少需要8GB显存。
没有GPU?Mac M1/M2/M3/M4的芯片也能跑,用mps加速:
device = "mps" if torch.backends.mps.is_available() else "cpu"
纯CPU也能跑,但会很慢。而且Python得3.10以上。
安全水印:负责任的AI
这个细节挺有意思的。所有Chatterbox生成的音频都内置了PerTh水印(Perceptual Threshold Watermark),这个水印是人耳听不到的,但能被程序检测到。即使音频被压缩、编辑、修改,水印还能检测到,准确率接近100%。
这个是Resemble AI的PerTh Watermarker技术,算是负责任的AI实践。不用担心被滥用做坏事,因为每个生成的音频都能溯源。
提取水印的代码:
import perth
import librosa
AUDIO_PATH = "YOUR_FILE.wav"
watermarked_audio, sr = librosa.load(AUDIO_PATH, sr=None)
watermarker = perth.PerthImplicitWatermarker()
watermark = watermarker.get_watermark(watermarked_audio, sample_rate=sr)
print(f"Extracted watermark: {watermark}")
返回1.0表示有水印,0.0表示没有。
实际应用场景:能干嘛?
说了这么多,这东西到底有什么用?给几个思路。
1. 智能客服
零样本语音克隆,可以让客服声音保持一致。不同客服说的都是同一个人的声音,用户体验更好。Turbo版本延迟低,还能实时生成,完美匹配智能对话场景。
2. 有声内容制作
小说、新闻、教程,这些文字内容可以用Chatterbox转成语音。夸张度调高,情感调好,生成的语音比机械的TTS自然多了。多语言版本还能轻松做多语言内容。
3. 语音助手/语音交互
Turbo版本就是为这个生的。200ms延迟,几乎感觉不到延迟。加上副语言标签,生成的语音会更有亲和力。比如:
text = "好的,我明白了 [chuckle],让我来帮你查一下。"
4. 内容创作辅助
做视频、做播客,不想自己录音?找一段喜欢的声音当参考,让Chatterbox帮你配音。省时省力,效果还不赖。
5. 语言学习
多语言版本可以生成23种语言的语音。学日语?让Chatterbox用日语念课文,还能调节语速和情感。比单纯看文字有效多了。
6. 无障碍应用
视障人士可以用语音访问更多内容。零样本克隆可以让APP用用户熟悉的声音说话,体验更亲切。
还有一些小技巧
参考音频选择:清晰、无噪音、说话人语速适中的音频效果最好。语速过快或过慢会影响生成质量。
文本预处理:Chatterbox会自动处理一些标点符号,但中文的标点还是要注意一下,用半角逗号、句号比较好。
批量生成:模型加载后可以重复使用,不要每次generate都重新加载模型。批量生成的话,把所有文本准备好,循环调用generate就行。
Mac用户:记得设置device为"mps",能利用苹果芯片的加速。example_for_mac.py里有完整的示例。
写在最后
Chatterbox不是第一个开源的语音克隆项目,但肯定是最好用的之一。三个模型版本满足不同需求,23种语言支持国际化,零样本克隆降低了使用门槛,内置水印保证了安全性。
最关键的是,它真的好用。几行代码就能跑起来,效果还不错。如果你对语音克隆感兴趣,或者想在项目里集成TTS功能,这个项目值得看看。
技术这东西,说白了就是工具。好不好用,适不适合自己,试过才知道。
GitHub:https://github.com/resemble-ai/chatterbox
官方Demo:https://huggingface.co/spaces/ResembleAI/chatterbox-turbo-demo
多语言Demo:https://huggingface.co/spaces/ResembleAI/Chatterbox-Multilingual
有兴趣自己试试吧,玩出花样了别忘分享一下。