老规矩,先上GitHub项目地址:https://github.com/MiroMindAI/MiroThinker
这一天终于来了
说实话,做开源项目搬运工这么多年,见过无数AI项目,有花里胡哨的,有吹上天的,但真正让我坐直了身子的项目,真的不多。
今天要说的这个,不一样。
它叫MiroThinker,一个能真正"思考"的AI Agent。不是那种你问个问题它就扔给你ChatGPT答案的玩具,而是能自己规划任务、调用工具、持续跟进,直到把活儿干完的智能体。
最关键的是,它开源了。
MiroThinker到底是什么鬼?
用最简单的话说,MiroThinker是一个具备强大工具调用能力和长上下文理解能力的大模型Agent框架。
它的核心卖点(或者说让人眼红的地方):
超长上下文
:v1.0版本支持256K上下文,v1.5版本更进一步,这意味着它能记住你一个小时的对话不跑题(某些人类都不行)
疯狂的工具调用次数
:v1.0最多600次,v1.5升级到400次交互式扩展。简单说,它能在一个任务里连续操作几百个步骤
智能推理引擎
:基于MiroFlow框架,像真正的程序员一样拆解任务、规划路径、处理异常
研究级任务能力
:不仅会写代码,还会搜论文、爬数据、跑实验,简直是科研人员的救星

实战教程:让MiroThinker为你打工
好了,吹归吹,东西好不好用得看疗效。下面直接上干货,手把手教你把这个强大的AI Agent部署起来。
第一步:环境准备
别慌,这一步不复杂。
你需要准备以下几样东西:
一台配置还可以的电脑(建议至少16GB内存,有GPU更好)
Python 3.10或更高版本
一点点的耐心(部署大模型总归要花点时间)
第二步:克隆项目
打开你的终端,执行:
git clone https://github.com/MiroMindAI/MiroThinker.gitcd MiroThinker
这时候你的本地就有完整的项目代码了。项目结构很清晰,主要包含:
apps/:各种应用,包括gradio-demo(网页演示)、miroflow-agent(核心Agent)、visualize-trace(跟踪可视化)等
libs/miroflow-tools/:工具库,各种功能模块
assets/:文档和资源
第三步:模型部署(关键!)
MiroThinker本身是个模型框架,你得先给它找个"脑子"。
项目支持多种部署方式,这里推荐两种最实用的:
方案A:使用SGLang或vLLM部署(推荐有GPU的用户)
如果你有一张不错的GPU显卡,这是性能最好的方案。
SGLang部署示例:
pip install sglangpython -m sglang.launch_server --model-path Qwen/Qwen2.5-72B-Instruct --tp 1 --port 8000
vLLM部署示例:
pip install vllmpython -m vllm.entrypoints.api_server --model Qwen/Qwen2.5-72B-Instruct --trust-remote-code
这里用的是Qwen2.5-72B模型,你也可以换成其他兼容的模型。
方案B:使用llama.cpp量化部署(推荐CPU用户)
没有GPU?没关系,llama.cpp能让你的CPU也能跑大模型。
具体步骤:
安装llama.cpp
下载量化好的模型权重
运行推理服务
详细参数配置可以参考项目的文档,这里不展开了(不然文章太长,读者要睡着了)。
第四步:配置MiroFlow Agent
模型启动后,你需要配置Agent框架。
进入miroflow-agent目录:
cd apps/miroflow-agent
配置文件在conf目录下,你可以根据自己的需求修改参数,比如:
模型服务地址
工具调用策略
上下文保留策略
Agent数量(单Agent还是多Agent协作)
第五步:启动Gradio演示界面
想直观体验MiroThinker的能力?启动Web界面:
cd apps/gradio-demopython main.py
然后在浏览器打开localhost:7860,你就能看到交互界面了。
在界面上,你可以直接输入任务,比如:
"帮我分析一下最新的深度学习论文,找出关于Transformer改进的思路,并给出代码示例"
MiroThinker会自动:
规划任务步骤
搜索相关论文
阅读并理解内容
提取关键技术点
编写示例代码
给出详细解释
全程自动化,你只需要等结果。
第六步:高级用法:跟踪采集与分析
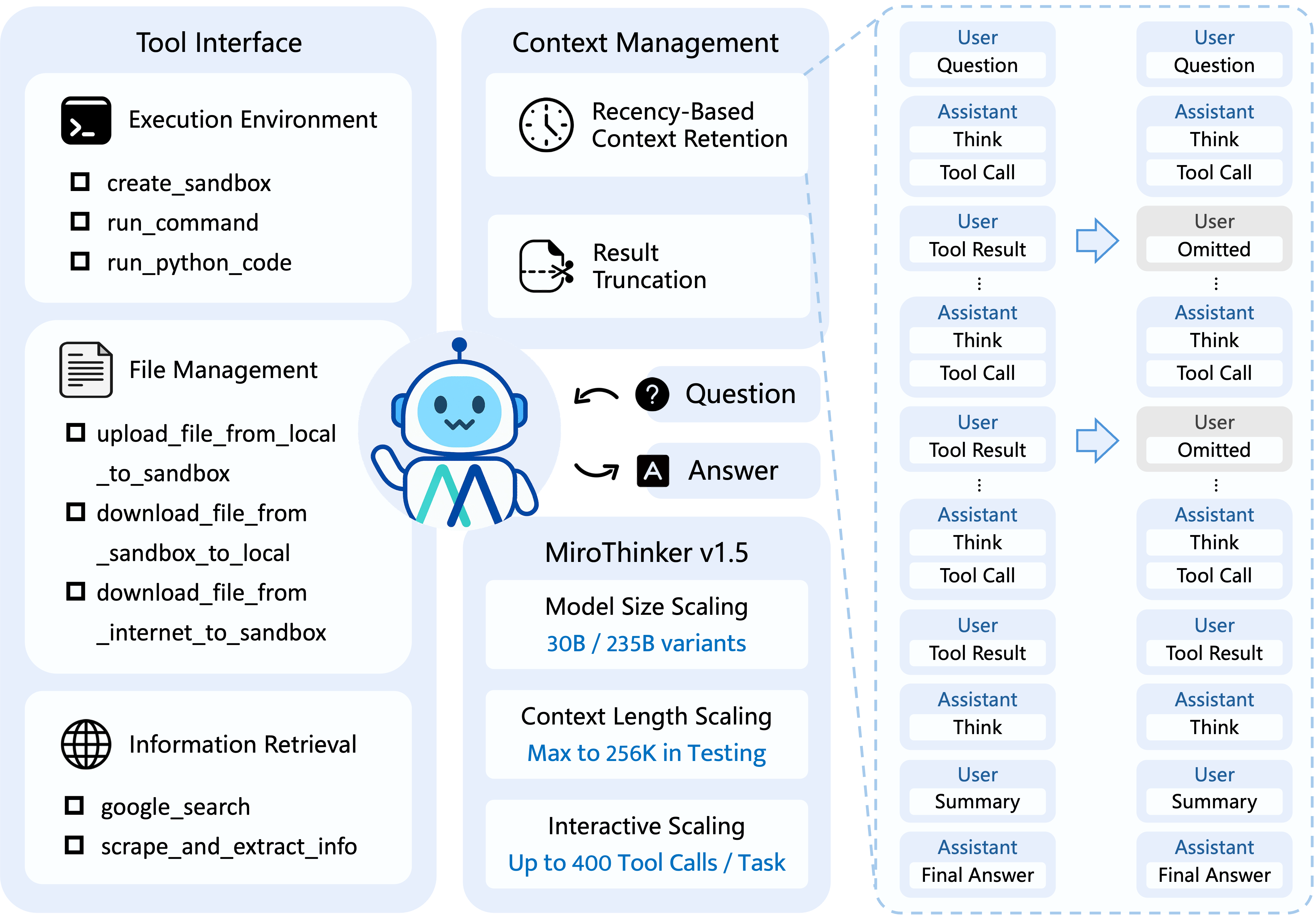
如果你是个技术控,想深入了解MiroThinker的思考过程,可以使用跟踪采集功能。
启动跟踪采集:
cd apps/collect-trace# 按README.md配置参数python scripts/collect_trace.py
采集后的数据可以用visualize-trace工具可视化:
cd apps/visualize-tracepython app.py
这能让你看到Agent的每一步决策过程,像打开黑盒一样观察它的"思考轨迹"。对于研究AI Agent行为模式的人来说,这简直是宝藏。
实际应用场景(让AI为你赚钱)
说完了怎么部署,最重要的部分来了:这玩意儿到底能干什么?
场景一:自动化科研助手
想象一下,你正在做一个机器学习研究项目,需要:
搜索相关领域的最新论文
提取关键方法和数据集信息
对比不同算法的性能
复现论文中的实验代码
通常这个过程可能需要几天甚至几周。用MiroThinker,你只需要一句话:"帮我调研一下2024年大模型推理优化的最新进展,总结主流方法并实现一个示例"。
然后你就可以去喝咖啡了。
场景二:智能代码审查与优化
作为开发者,我们经常要:
审查团队成员的代码
发现潜在的性能瓶颈
提供优化建议
编写单元测试
MiroThinker可以自动化这个过程:
读取代码库
分析架构和实现
识别问题和改进点
生成优化建议
自动编写测试用例
它不会累,不会发脾气,还能保持一致的质量标准。
场景三:复杂数据分析与报告
公司需要一份行业分析报告,涉及:
多个数据源的数据收集
数据清洗和预处理
统计分析和可视化
趋势预测和结论提炼
传统做法是分析师手动处理,耗时耗力。MiroThinker可以:
并行调用多个数据接口
自动化处理流程
生成可视化图表
输出结构化报告
老板要报告,你只需要点一下按钮。
场景四:自动化测试与质量保证
软件测试是一个重复性高但又至关重要的工作。MiroThinker可以:
分析需求文档,生成测试用例
自动化执行测试脚本
收集测试结果并分析
生成测试报告和问题清单
让AI帮你做测试,人类测试人员可以专注于更复杂的场景设计。
场景五:知识库构建与问答系统
企业内部积累了大量文档,但查找困难。MiroThinker可以:
批量读取文档内容
提取关键信息和关系
构建知识图谱
提供智能问答服务
员工问什么,它都能快速找到答案并给出解释。
写在最后
AI Agent正在重塑我们的工作方式。那些重复、繁琐、流程化的任务,正在逐步被自动化。
MiroThinker不是要取代人类,而是要成为人类最得力的助手。它能处理那些耗时耗力的工作,让我们把精力集中在更有创造性的事情上。
开源社区的力量在于,每个人都可以使用、改进、贡献。MiroThinker只是一个开始,未来会有更多强大的Agent框架涌现。
现在,轮到你了。
去试试吧,说不定你会挖掘出更多有趣的应用场景。毕竟,工具再强大,也要看怎么用,对吧?